

Deploying predictive models, and why the modelling algorithm is perhaps the easiest aspect of the problem.
Predictive models, specifically propensity models, are a staple of data science practice across organizations and verticals. Be it to understand whether a customer is likely to respond to an offer, or whether a borrower is likely to default, we find them applied in a variety of situations. In specific verticals such as financial services, their use is so prevalent that one finds entire divisions devoted to the care, feeding and updating of these models.
However, as is the case with so many things where we confuse volume for variety, the majority of these problems, as well as what we need to do to solve them, are standard. This implies that it is very much possible to productize model scores. Here are some of the common features of these models, and what they imply for someone trying to productize, or at least streamline, model building.
Problem statements
Most models end up falling into one of the following categories:
- The propensity of a customer to transact in the next n days, either in general or in a specific product category
- The propensity of a customer to respond to a specific offer (as a function of both offer and customer features)
- The propensity of a customer to churn, either implicitly (i.e., through inactivity for a certain period) or explicitly (i.e., account closure)
It is therefore possible to provide, with minimal configuration options, a set of standard models out of the box. These standard models will cover the majority of use cases.
Typical configuration options that make sense are:
- What is the response horizon?
- What is the nature of response being predicted? Transaction, Cart addition, Closure etc.
- What are the products being tracked? All products, products in a specific category etc.
- Is the model restricted to:
- Active customers
- Customers who have purchased this product before
- Customers who have never purchased this product before
- Unrestricted – applies to all customers
Feature engineering
The features used in most of these models are similar, and involve a standard set of patterns of extraction and preprocessing. Depending on the model, some specialized features might be called for, but these are, by and large, small modifications to a general feature set.
It is possible to standardize feature engineering for the most part. The ones that typically matter are:
- RFM and related features
- Preferences on product attributes, price, time, location channel, etc
- Response to past marketing outreaches
- Socio-demographics if available
- Service history, if any
- Preferences for the relevant product subset, if applicable (for instance, if the model predicts the propensity to buy Menswear, has the customer already exhibited a preference for this category?)
Additionally, for businesses where the value of the product is relevant to transactions (share price, NAV of a mutual fund etc), features pertaining to these aspects might be useful.
Model building pipeline
Model relevance depends on regular retraining and scoring, especially in businesses where the pattern of customer behaviour might be very dynamic.
ML Ops matters. One can set up a standard pipeline that is scheduled to run regularly, and retrain and rescore models with updated data on a regular basis. Since features and models are standardized, this does not require ongoing manual effort once it is set up. One can also create a mechanism to track performance on standard metrics such as recall at various deciles, area under the ROC curve etc.
A typical pipeline to train a model can be as follows. Consider a model to predict whether customers will transact between March 1-7, 2024. The predictors for this model would be whatever we know about each customer as of 29 February.

In order to train this model, the easiest thing to do is to go back by a week. That is, find out what you know about your customers as of 22 February, observe responses between 23-29 February, and build a model to correlate the two.

Figure 2 Training data measurement
The model built based on the above data can be used to score customers as of 29 February. In order to test whether the approach works well when applied at a later time point, one can also build an additional model based on responses between Feb 16-22, and then use that model to score data for the week following (generated as described in Figure 2 above), and then compare the scores against reality (we already know who transacted between Feb 23-29) to get a performance measurement.
The overall pipeline now looks like this:
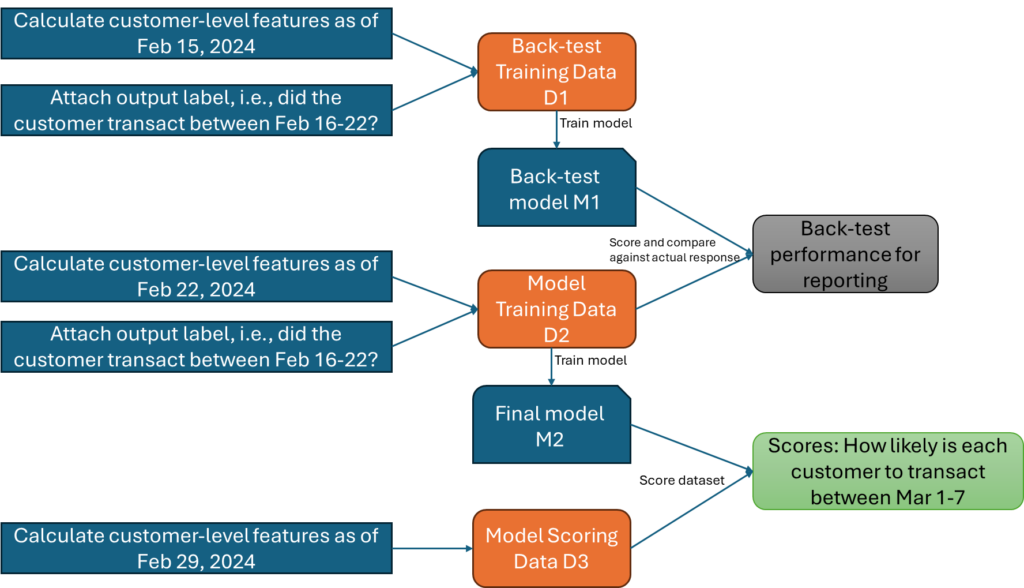
Figure 3 Training and scoring pipeline for model to predict transactions in the next 7 days
The exact same pipeline can be updated to work every seven days so that the model is kept up to date. The interesting thing is: it applies even when we need to customize certain aspects. For instance:
- It is possible, in order to account for seasonal behaviour, to specify the response window dates manually, e.g., when one wishes to predict response during an end-of-season sale (EOSS), the response window to train the model would be the dates of the previous EOSS.
- If one wishes to add customized features specific to a particular client, all that is needed is for us to add a mechanism to insert custom feature computation code in the above pipeline, while computing customer level features. The rest remains the same.
Modelling technique and Explainability
In reality, the modelling algorithm seldom matters for most problems. The performance of various modelling algorithms is usually comparable. While nonlinear machine learning algorithms do a bit better than logistic regression in a number of cases, there is little to choose between these ML models themselves. What people might look for, however, is explainability.
Model explainability is often asked for by decision makers who use them. However, explainability doesn’t always mean being able to simplify the functional form to the point where it is easy to make out what leads to the final score.
Often, what is required is simply an explanation of the various features that go into the model, along with their relative importance in the final model.
We can choose an approach where fine-tuning is minimal, the libraries are reliable and efficient, and there is support for simple things like categorical variables, missing data etc. without having to build complex preprocessing pipelines. As for explainability, it is possible to set up a standard, model-agnostic pipeline to estimate feature importance in a model.
For instance, if you shuffle one feature while keeping the others constant, and check the performance degradation as a result, you can expect to find that the more important features cause more degradation when they are shuffled. Simply shuffle one feature at a time and order them based on how much worse the model does when you do.
Additionally, if you know already that you’re likely to pick the top 3 deciles for a campaign, simply run a decision tree to classify people in the top 3 score deciles versus the bottom 7 – this is not the same as the actual model, but can give you a simple rule that explains, at a somewhat coarse level, what is common to the customers with high propensity scores.
In conclusion…
We tend to think of propensity modelling problems as the province of data scientists. To a certain extent, this is true; however, it helps to recognize that:
- While there is a long tail of specialized problems that require bespoke model builds, the vast majority of problems are well understood and commoditized
- Even for bespoke problems, the vast majority of things to do in order to build the model (feature engineering, training and validation, routine recalibration etc) are well understood and commoditized
This in turn means that decision makers can be armed with a variety of propensity scores for personalized targeting, with very little effort. This can considerably improve the effectiveness of their marketing outreach efforts.



